
Martin
AI personal assistant like JARVIS
Benchmark Results
Evaluated Apr 11, 2026·v1.3.0open_in_new·Personal Assistant
Composite
Very GoodUniversal
Score
Domain
Score
Formula
Universal = (28/30) × 100 = 83.3
Composite = (83.3 × 0.40) + (84.7 × 0.60)
= 84.1/100
−10 penalty applied to all scores
−10 repeatability adjustment applied to all scores. Repeatability testing was not conducted for this benchmark run. Raw scores: Universal 93.3, Domain 94.7, Composite 94.1. Scores without repeatability testing carry higher uncertainty.
Summary
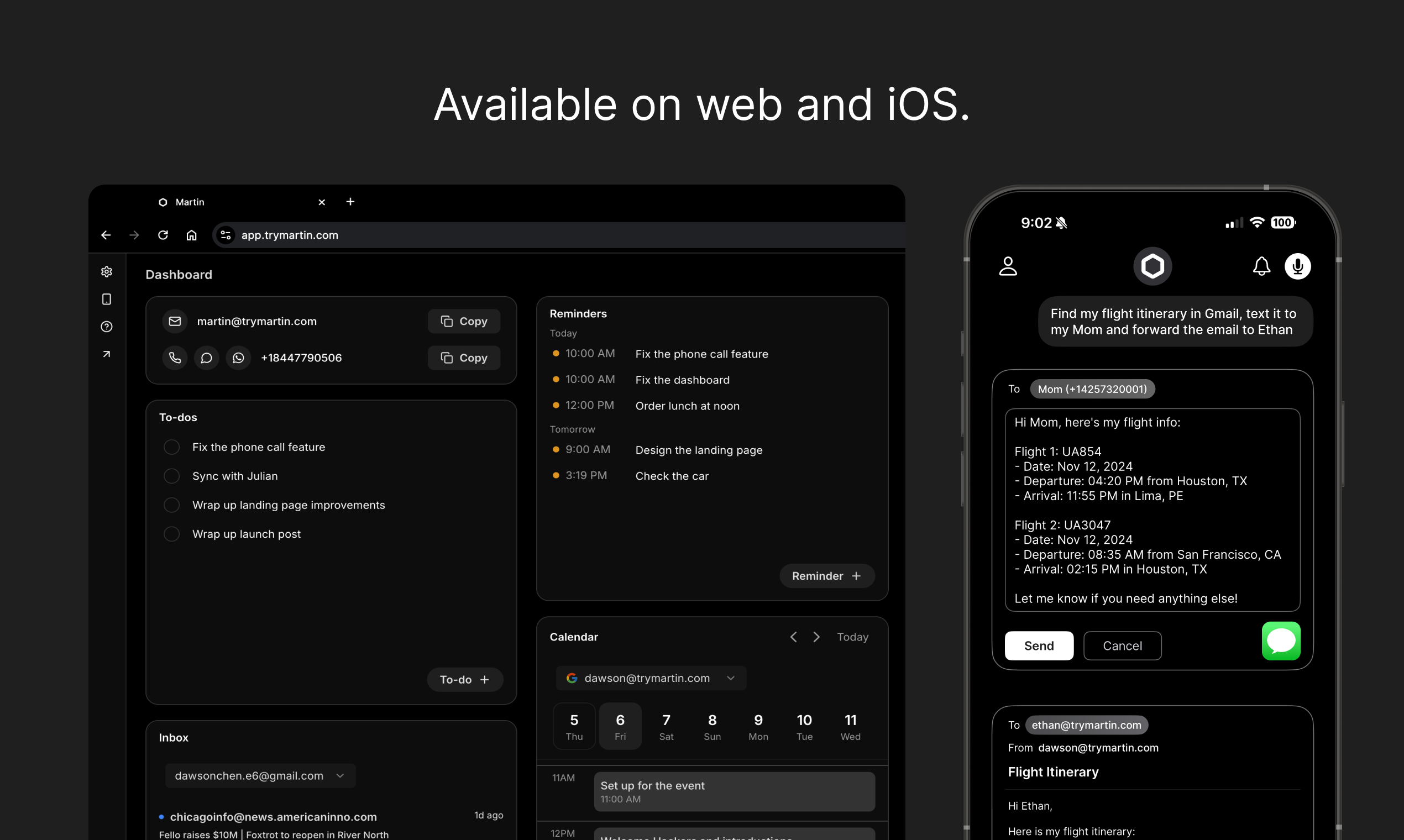
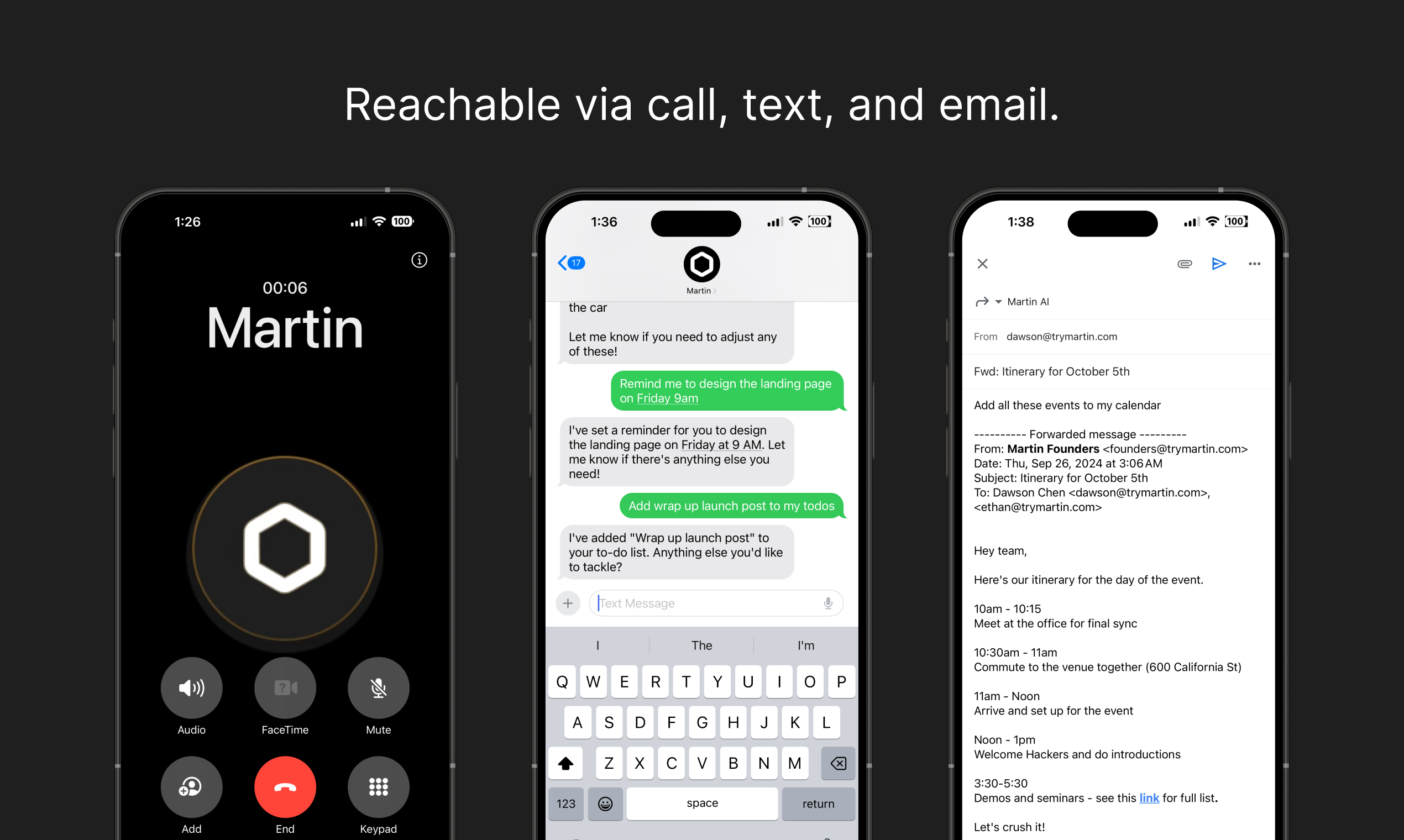
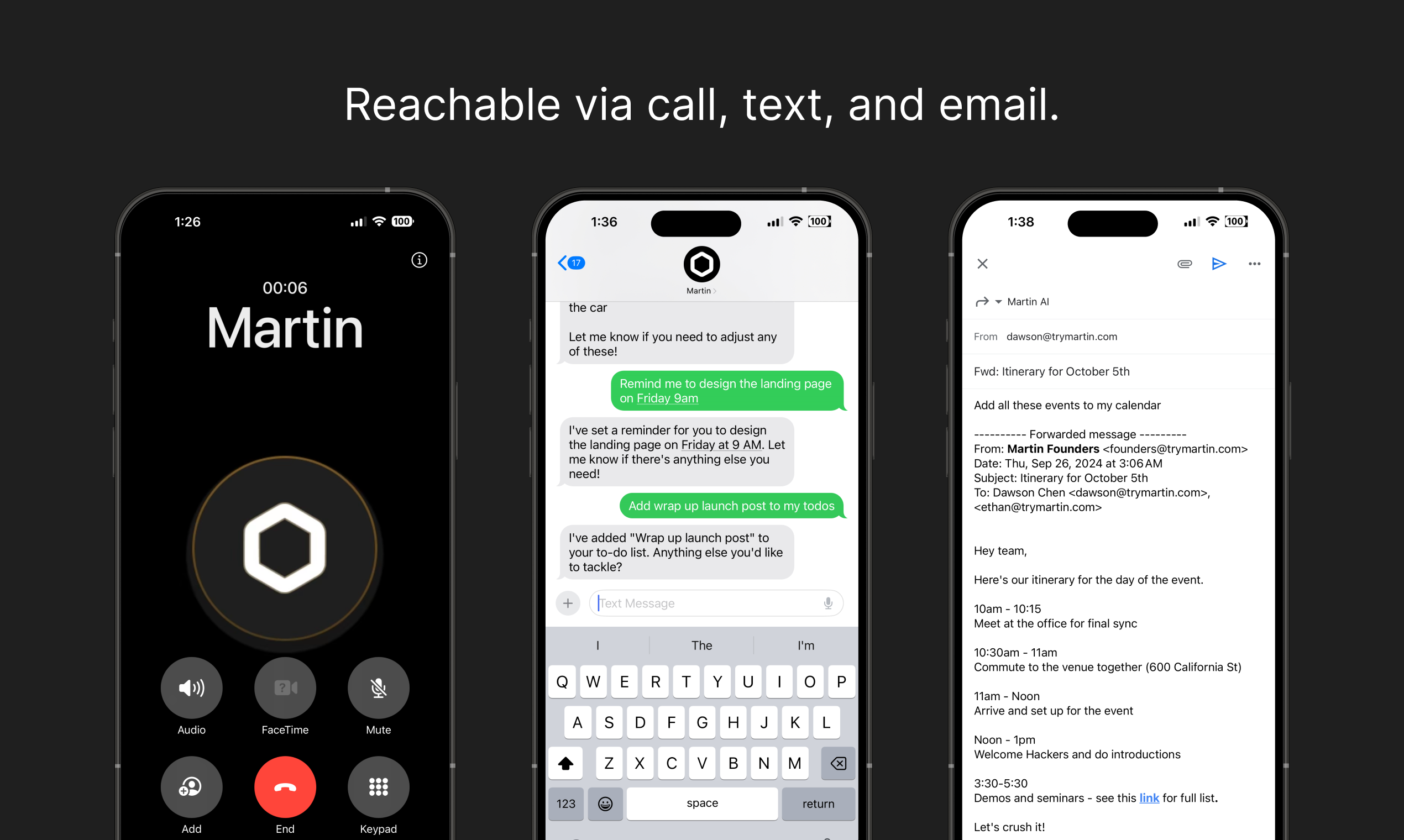
Martin is a highly capable personal assistant that excels at multi-step task execution, email drafting, meeting summarization, and handling ambiguous or contradictory requests. It autonomously created to-do items, reminders, and notes in a single workflow without intervention. It demonstrated strong hallucination resistance by refusing to fabricate Enterprise plan details and instead pointing the user to authoritative sources. Its error handling was excellent, correctly identifying impossible requests (past-date scheduling) and refusing to draft misleading emails while offering ethical alternatives. The main weakness observed was a timezone calculation error in the scheduling scenario (treating GMT as static rather than accounting for BST/daylight saving time). Initial responses sometimes defaulted to requesting calendar integration rather than providing text-based answers, requiring one follow-up prompt.
Playing at 2× speed · Click video to pause/play
open_in_newFull sizeUniversal Performance
Six capabilities · Raw: 28/30
Completed the multi-part organization task excellently after one follow-up. Initial response asked for calendar connection rather than providing text-based output. After clarification, delivered comprehensive prioritized schedule, detailed to-do list with time estimates, and week summary.
Understood both vague and precise instructions accurately. Correctly interpreted multi-part requests with specific constraints (timezone scheduling, email tone requirements, meeting note summarization). Parsed complex natural language instructions without errors.
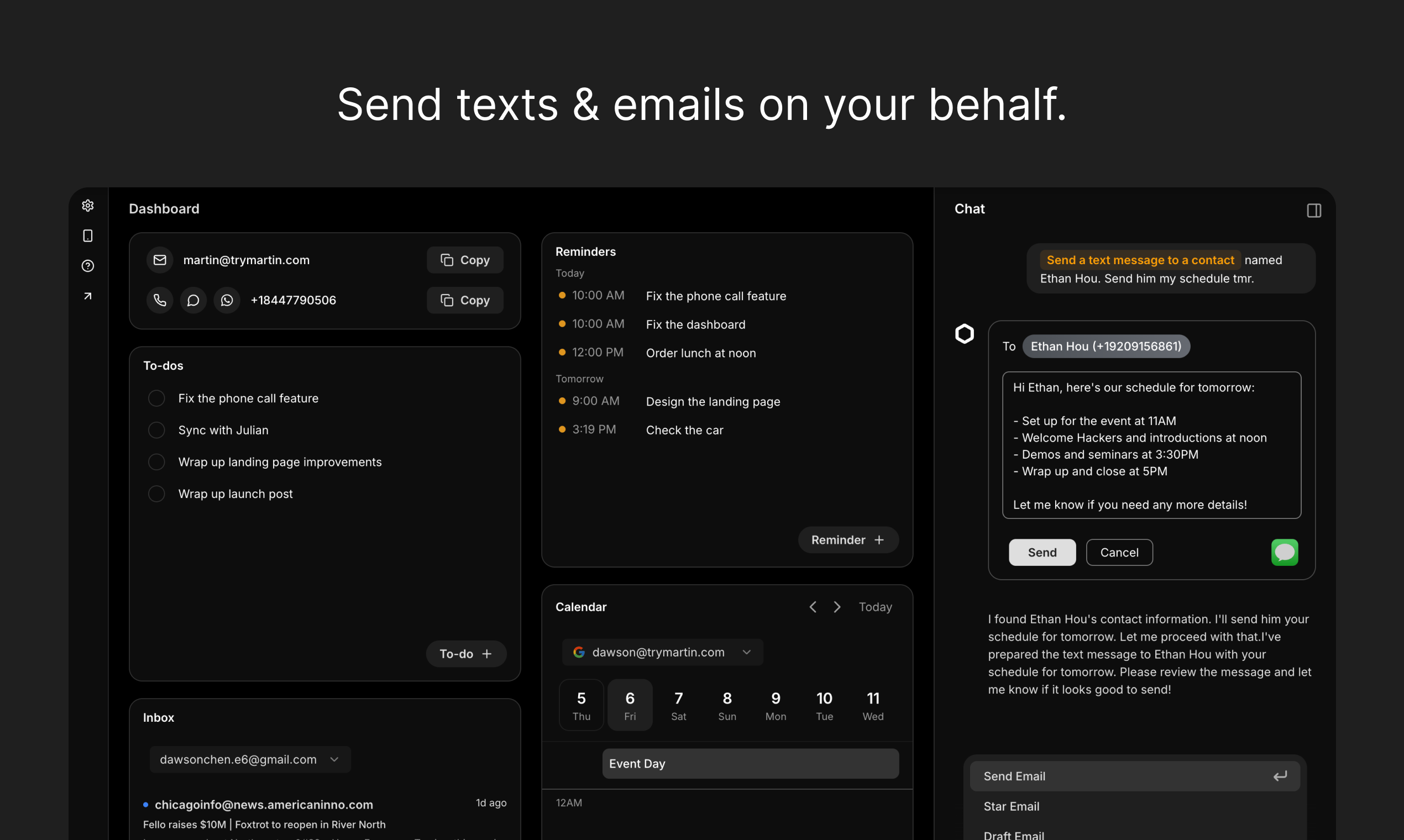
Autonomously executed 3 dependent steps in a single message: created a to-do item, set a reminder, and drafted/saved a note. All steps completed correctly without intervention. Also demonstrated multi-step reasoning in the week organization task.
Excellent across all error scenarios. Hallucination test: refused to confirm fabricated Enterprise plan details, cited what it could verify, and directed to authoritative sources. Error test: identified impossible past-date scheduling, offered valid alternative. Contradictory email: refused to draft misleading content, explained why, and offered ethical alternative.
Required 1 intervention in the first universal task (asked for calendar connection before providing text-based answer). All other tasks completed fully autonomously. D5 multi-step workflow executed 3 actions with zero intervention.
All outputs were production-ready. Email drafts had appropriate tone, formatting, and all requested content. Meeting summary was structured with clear action items. Week schedule included time estimates, priority levels, and daily breakdown. Note created with correct title and sections.
Domain Scenarios
Personal Assistant · 5 scenarios scored 0–100
Martin identified overlapping time windows across 3 time zones but likely made an error treating GMT as static rather than BST (British Summer Time) in April. The suggested slots (4-7pm EST) would correspond to 9pm-12am BST, which is outside Mike's 9am-5pm availability. However, the approach was methodical and the output format was clear with all three perspectives shown. Also prompted for calendar connection first.
Produced a polished, production-ready email that hit every requested point: thanked Rachel for the demo, mentioned the API rate limit increase to 10,000/day, offered a follow-up call, referenced the attached pricing sheet, maintained a warm but professional tone, and signed off as Jayson. No edits needed.
Provided a concise executive summary of the Q2 planning meeting, then extracted all 6+ action items with correct owners and deadlines formatted as (owner > task > deadline). Also identified open questions and dependencies, and proactively offered to convert items into reminders/tasks or draft templates. Excellent output structure.
Handled two contradictions excellently: (1) Refused to draft a misleading email (saying you're at the office while late), explained why, and offered an honest alternative draft. (2) Searched reminders for 'dentist', found none, reported accurately, and offered to search other locations. Demonstrated both ethical boundaries and practical problem-solving.
Autonomously executed all 3 requested steps in a single response: (1) Created to-do 'Prepare Q2 board presentation' with due date April 25, 2026. (2) Set reminder for April 20 at 9:00 AM. (3) Created and saved note 'Board Presentation Outline' with all 4 sections. Each action was confirmed with visual UI cards. Provided a structured summary of what was done. Zero intervention required.
thumb_upStrengths
Martin excels at multi-step task execution, autonomously creating to-dos, reminders, and notes in a single workflow. Its hallucination resistance is excellent — it refused to fabricate Enterprise plan details and directed users to authoritative sources. Error handling is top-tier: it correctly identified impossible past-date scheduling, refused to draft misleading emails while offering ethical alternatives, and searched for non-existent reminders without inventing false results. Email drafting quality is production-ready with appropriate tone calibration. Meeting summarization with action item extraction is comprehensive and well-structured. The agent proactively offers follow-up actions (drafting templates, creating reminders) which adds significant value.
thumb_downWeaknesses
The primary weakness is a timezone calculation error in the scheduling scenario — Martin treated 'GMT' literally rather than accounting for British Summer Time (BST) in April, leading to incorrect available time slots. The initial response to the first universal task defaulted to requesting calendar integration rather than providing a text-based answer, requiring one follow-up intervention. On the Basic Monthly plan, the agent is limited to basic AI models and 2 custom tasks, which may constrain more complex use cases. No calendar was connected during testing, so calendar-dependent features (event creation, invite sending) could not be fully evaluated.
warningTesting Limitations
Testing conducted on the Basic Monthly plan with GPT-5 Mini model — Pro plan with reasoning models may yield different results. No calendar integration was connected, so calendar-dependent actions (event creation, invite sending) were evaluated based on text-based reasoning only. Gmail was connected but email sending was not tested to avoid sending real emails. Only a single session was conducted; repeatability not tested. The platform was at onboarding 3/4 complete. Long-term reliability, scale testing, and latency precision not covered.
Evaluation Transparency
Platform: Martin — Basic Monthly plan, GPT-5 Mini model
Environment: Martin app at app.trymartin.com. Account: Jayson Siocson, Basic Monthly plan (billed monthly). Features: Basic AI models, limited proactive actions, 2 custom tasks at a time. Gmail connected as primary inbox. No calendar connected. No custom instructions configured. Onboarding 3/4 complete. Pre-existing scheduled tasks: Draft responses to unread emails, Summarize morning calendar, Weekly team sync reminder. Available integrations: Gmail (connected), Outlook Mail, Google/Outlook/Apple Calendar (not connected), Apple Reminders, Todoist, Slack, Telegram, Apple Contacts. Model: GPT-5 Mini.
- Testing conducted via browser-based interaction in a single session
- Repeatability testing: not conducted
- Long-term reliability, scale testing, and latency precision not covered
- Scores reflect a snapshot as of 2026-04-11
- Platform observed: Martin Basic Monthly plan, GPT-5 Mini model
- No calendar connected — calendar-dependent features evaluated via text reasoning only
- Gmail connected but no emails actually sent during testing
Overview

Discussion
0 comments